We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
General description of the gene and the encoded protein(s) using information from HGNC and Ensembl, as well as predictions made by the Human Protein Atlas project.
Gene namei
Official gene symbol, which is typically a short form of the gene name, according to HGNC.
All transcripts of all genes have been analyzed regarding the location(s) of corresponding protein based on prediction methods for signal peptides and transmembrane regions.
Genes with at least one transcript predicted to encode a secreted protein, according to prediction methods or to UniProt location data, have been further annotated and classified with the aim to determine if the corresponding protein(s) are secreted or actually retained in intracellular locations or membrane-attached.
Remaining genes, with no transcript predicted to encode a secreted protein, will be assigned the prediction-based location(s).
The annotated location overrules the predicted location, so that a gene encoding a predicted secreted protein that has been annotated as intracellular will have intracellular as the final location.
Summary of RNA expression analysis and annotation data generated within the Human Protein Atlas project.
Single cell type expression clusteri
The RNA data was used to cluster genes according to their expression across single cell types. Clusters contain genes that have similar expression patterns, and each cluster has been manually annotated to describe common features in terms of function and specificity.
Neurons - Neuronal signaling (mainly)
Single cell type specificityi
The RNA specificity category is based on mRNA expression levels in the analyzed cell types based on scRNA-seq data from normal tissues. The categories include: cell type enriched, group enriched, cell type enhanced, low cell type specificity and not detected.
The RNA data was used to cluster genes according to their expression across tissues. Clusters contain genes that have similar expression patterns, and each cluster has been manually annotated to describe common features in terms of function and specificity.
Non-specific - Transcription (mainly)
Tissue specificity (RNA)i
The RNA specificity category is based on mRNA expression levels in the consensus dataset which is calculated from the RNA expression levels in samples from HPA and GTEX. The categories include: tissue enriched, group enriched, tissue enhanced, low tissue specificity and not detected.
Tissue enhanced (Lymphoid tissue, Retina)
Subcellular locationi
Main subcellular location based on data generated in the subcellular section of the Human Protein Atlas.
Localized to the Mitochondria In addition localized to the Vesicles
Secretome annotationi
All genes with at least one predicted secreted isoform have been annotated and classified with the aim to determine if the corresponding protein(s) are:
secreted into blood
locally secreted
or actually being attached to membrane or retained in intracellular locations like mitochondria, endoplasmatic reticulum (ER), Golgi apparatus or lysosomes.
Not available
GENE INFORMATIONi
Gene information from Ensembl and Entrez, as well as links to available gene identifiers are displayed here. Information was retrieved from Ensembl if not indicated otherwise.
Chromosome
2
Cytoband
p16.1
Chromosome location (bp)
54723499 - 54972025
Number of transcriptsi
Number of protein-coding transcripts from the gene as defined by Ensembl.
Links to data of the different assays available in the Structure & Interaction resource of the Human Protein Atlas. Click on the miniature images to directly get to the respective section.
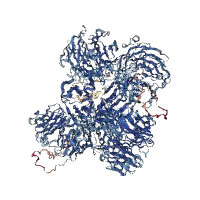
The Structure section provides in-house generated structures, predicted using the Alphafold source code, for the majority of the proteins and their related isoforms.
Displaying protein features on the AlphaFold structures
Individual splice variants can be selected in the top part of the Protein Browser (see below) and different transcript-related features such as transmembrane regions, InterPro domains and antigen sequences for antibodies can be displayed in the structure by clicking on the respective features in the Protein Browser.
Clinical and population-based amino acid variants based on data from the Ensembl variation database and AlphaMissense (AM) predictions can be highlighted using the sliders to the right of the structure. These can also be used to colour the entire structure by residue index or make the structure autorotate.The structures are displayed using the NGL Viewer and can also be zoomed-in and rotated manually.
The Protein Browser
The ProteinBrowser displays the antigen location on the target protein(s) and the features of the target protein. Transcript names and schematic transcript structures including exons, introns and UTRs for the different isoforms are shown on top, and can be used to switch between the structures for the different splice variants.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Below the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
Signal peptides (turquoise) and membrane regions (orange) based on predictions using the
majority decision methods
MDM and MDSEC are also displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
EML6_201
EML6-201
EML6-211
Description: Structure prediction of EML6-201 from Alphafold v2.3.2
Color scheme:
Confidence
Residue index
Your selection
Variants:
Off
Population (#=1200)
Clinical (#=0)
Alphamissense variants:
Off
Benign (#=16)
Pathogenic (#=13156)
Autorotate:
Off
On
Confidence for predicted structure:
Very high (pLDDT > 90)
Confident (90 > pLDDT > 70)
Low (70 > pLDDT > 50)
Very low (pLDDT < 50)
PROTEIN INFORMATIONi
The protein information section displays alternative protein-coding transcripts (splice variants) encoded by this gene according to the Ensembl database.
The Splice variant identifier links to the Ensembl website protein summary for the selected splice variant. The data in the Swissprot and TrEMBL columns links to corresponding pages in the UniProt database.
The protein classes assigned to this protein are shown if expanding the data in the protein class column. Parent protein classes are in bold font and subclasses are listed under the parent class.
The length of the protein (amino acid residues according to Ensembl), molecular mass (kDalton), predicted signal peptide and number of predicted transmembrane region(s) according to in-house majority decision methods based on sets of predictors are also reported.
In the Interaction part of this page network plots showing the gene's interaction partners according to four different datasets are displayed, including a consensus network plot showing only interactions present in at least two of the datasets. In the network plots the nodes represent genes and edge color represent the number of datasets the interaction belongs to.
The highlight bar in the top of the plot can be used to color the nodes according to subcellular location (based on data in the Subcellular section), predicted location (based on signalpeptide and transmembrane region predictions), tissue specificity (based on RNA tissue expression profiles) or proteinclass. For genes categorised as single cell type or group specific the option to highlight interaction partners expressed in the same cell type will also be available in the highlight bar.
Custom highlighting of nodes is possible using the top left Filter option in which a query of choice can be built to for example label all nodes that are tissue enriched in both human and mouse brain or those that belongs to a certain tissue expression cluster. The expression cluster for the gene is stated in the box Human Protein Atlas Information above the network plot. Click on Filter in the top left in the plot to find the query builder and some example queries.
Interactions included are direct interaction and physical associations with high and medium confidence from IntAct, physical multivalidated interactions from BioGRID, interactions with>75% probability from BioPlex and significant physical interactions from OpenCell.
EML6 has no defined protein interactions in Consensus.
EML6 has no defined protein interactions in IntAct.
EML6 has no defined protein interactions in BioGrid.
EML6 has no defined protein interactions in OpenCell.
EML6 has no defined protein interactions in BioPlex.
METABOLIC SUMMARYi
In this summary the pathway/subsystems to which the gene belongs is shown together with the associated cellular compartment for the reactions based on metabolite information. The number of proteins and metabolites in the pathway is shown as well as the number of reactions for the selected gene. By clicking on a pathway in the summary table the associated metabolic network map is shown, together with a gene-tissue heatmap that shows the expression of genes in that pathway in different tissues.


 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded